An Analysis of the Top 1000 Go Repositories
Jan 2, 2016 · 9 minute read · CommentsGoGit
This analysis was done from copies cloned on January 2, 2016 early morning Pacific Time.
Code organization
Most code is a library, so the code is organized as either .go files under the main repo, or as .go
files under sub-directories. Many people also organize their code under a sub-directory, like
/src, /lib/, /go/, or /pkg/. I can’t manually inspect all of the repositories, but those
I did check are apps written in go rather than libraries. Using go get would fail on them because
of the directory structure.
At least one of the repositories seems to use the developer’s $GOPATH as the repository root,
which would certainly make developing it alongside anything else impractical.
oniony/TMSU:src/github.com/oniony/TMSU/cli/mount.go
Tumblr also seems to use the same model, but they have their own mini-monolithic repository with a
ton of packages under the /src directory
tumblr/gocircuit:src/tumblr/redis/redis.go
tumblr/gocircuit:src/circuit/kit/debug/ctrlc/init.go
Vendoring
It’s done nearly as many ways as there are repositories. In order to pick out the source files for each project, I scrolled through all 50-thousand-odd files in an intermediate list to see if there were any vendored packages. I wanted to exclude them generally for analysis, but it’s quite difficult because of the variety of ways vendoring is done.
Some people store external dependencies in special folders, with names like:
- Godeps
- vendor
- _vendor
- third_party
- _third_party
- 3rdparty
- external
Or alongside their own code (e.g.):
yinqiwen/gsnova:src/code.google.com/p/go.crypto/ssh/terminal/util.gocloudfoundry-incubator/lattice-release:src/github.com/docker/docker/pkg/archive/changes_linux.gotardisgo/tardisgo:goroot/haxe/go1.4/src/runtime_replaced/iface.govole/vole:src/code.google.com/p/go.net/ipv4/header.gogetlantern/lantern:src/golang.org/x/tools/go/ssa/interp/reflect.gomindreframer/golang-stuff:github.com/moovweb/gokogiri/html/document.gomindreframer/golang-devops-stuff:src/github.com/dotcloud/docker/daemon/graphdriver/btrfs/btrfs.gohyperhq/hyper:lib/docker/pkg/system/utimes_freebsd.go
Open Source Books and Websites
Many books and websites exist as public repositories on Github:
- adonovan/gopl.io
- Unknwon/the-way-to-go_ZH_CN (A few from Unknwon, actually)
- studygolang/studygolang
I’m a big fan of this approach, mostly because the community can send pull requests and fix things that need a bit more clarification, or edit the work so it stays a living document of the subject matter. I also keep my blog as a public repository because I don’t think it makes sense to hide something that’s already public.
Age
The pace has been picking up over time for creation of great Go projects:
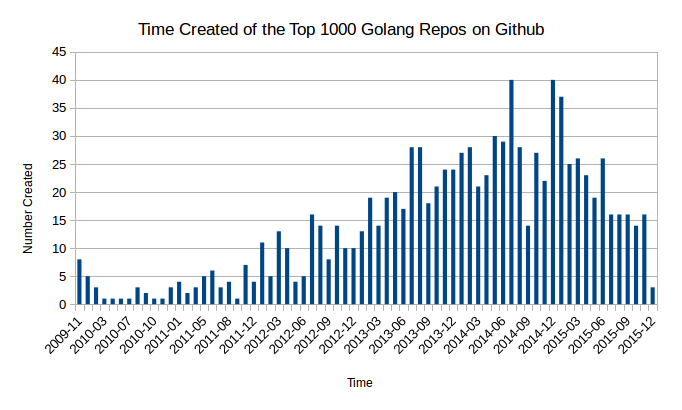
Of the top 1000, 815 were updated in the last 7 days (with some possible play because I can’t
download all repos at exactly the same time).
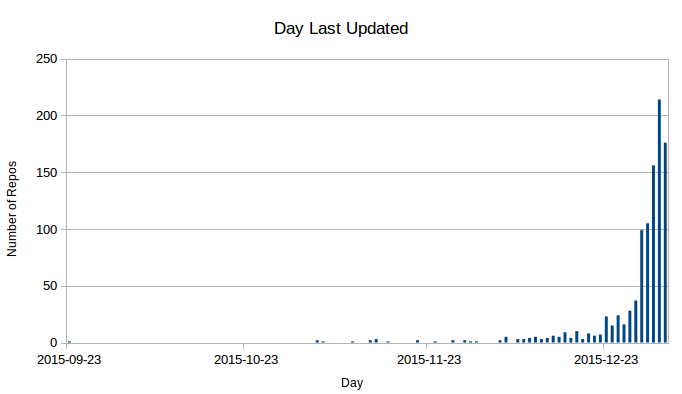
Overall, the speed of the popular repositories is higher than that of the community at large, which could possibly be explained by the size of the developer pool. I would hazard a guess that the popular repositories have a snowball effect, where more developers join over time and thus the velocity increases. I have the git histories, but haven’t done this analysis.
Repositories per Organization / User
I counted the number of top 1000 repositories each organization (or user) had on GitHub, with some
interesting, but obvious results. Many are concentrated under just a few umbrellas, with a long tail
of people with a single repo in the top crowd. The pattern, interestingly enough, follows a pretty
clear exponential curve.
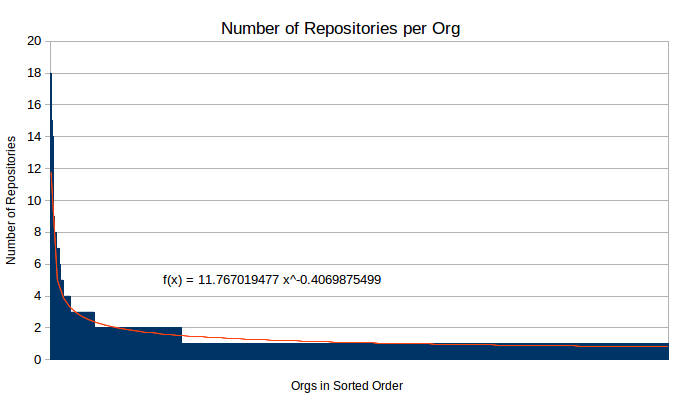
Unsafe, Reflect, and CGo
In Go, the “power tools” are the unsafe and reflect packages and CGo, which provides integration with C.
From this output, you can see that out of roughly 50 thousand files, very few use any of the three:
scott@devbox:/tmp/ghgo$ wc -l *_by_*
7 cgo_by_org
7 cgo_by_repo
323 reflect_by_org
413 reflect_by_repo
165 unsafe_by_org
195 unsafe_by_repo
1110 total
Unsafe
Unsafe is used to get around the type system in Go. It is useful when dealign with CGo to deal with raw pointers, but otherwise is typically not used. Interestingly, usage of unsafe is far higher than the usage of CGo.
Top org usage of unsafe:
- 360: golang
- 178: tardisgo
- 156: getlantern
- 87: mindreframer
- 66: andlabs
- 36: google
- 35: qur
- 35: lxn
- 34: docker
- 29: libgit2
Top repo usage of unsafe:
- 300: golang/go
- 178: tardisgo/tardisgo
- 156: getlantern/lantern
- 66: andlabs/ui
- 44: mindreframer/golang-devops-stuff
- 43: mindreframer/golang-stuff
- 35: qur/gopy
- 35: lxn/walk
- 29: libgit2/git2go
- 29: go-qml/qml
Reflect
Reflect is typically used for JSON unmarshalling or sometimes for testing. I haven’t vetted the usage in each of the packages that contain imports, so I don’t know each stated purpose. It is used quite heavily.
Top org usage of reflect:
- 134: mindreframer
- 94: kubernetes
- 89: golang
- 85: rainycape
- 75: getlantern
- 42: tardisgo
- 40: gocircuit
- 38: hashicorp
- 34: openshift
- 33: aws
Top repo usage of reflect:
- 92: kubernetes/kubernetes
- 85: rainycape/gondola
- 75: getlantern/lantern
- 72: mindreframer/golang-stuff
- 62: mindreframer/golang-devops-stuff
- 42: tardisgo/tardisgo
- 42: golang/go
- 28: ungerik/go-start
- 28: openshift/origin
- 28: juju/juju
CGo
CGo provides integration with C libraries. It is used in a few places, such as cockroachDB, to connect to a backing storage library written in C(++) such as RocksDB.
Top org usage of CGo:
- 6: lazywei
- 4: veandco
- 2: golang
- 2: getlantern
- 1: hybridgroup
- 1: go-python
- 1: gographics
Top repo usage of CGo:
- 6: lazywei/go-opencv
- 4: veandco/go-sdl2
- 2: golang/mobile
- 2: getlantern/lantern
- 1: hybridgroup/gobot
- 1: go-python/gopy
- 1: gographics/imagick
Source Code for Analysis
You will need jq and git installed:
- Mac OSX w/ homebrew:
brew install jq - Debian (and derivatives):
sudo apt-get install jq
You will also need about 10 gigabytes of free disk space in your /tmp/ directory.
The script takes a while to run, but produces all of the output used to write this article. It first
goes to GitHub’s search API (which is publicly available, no auth required) to retrieve the top 1000
repositories with Go as the language. It then clones all of the repositores in order to do further
analysis on the source code. Some basic statistics are extracted from the GitHub search results
first, like age of the repository. Then a more complex piece starts, where it looks for usage of the
unsafe and reflect packages as well as //#cgo comments. This analysis is done against a curated
list of files that excludes vendored dependencies, test files, and example code. The usage of unsafe
and reflect is measured in number of import statements in .go files from the final curated list, and
usage of CGo is measured in instances of //#cgo in the source code.
There’s a couple of things that I couldn’t figure out exactly, like re-using find results in
multiple egrep loops while respecting file names with spaces, but overall it gets the job done.
My final file lists were in the tens of thousands of files:
scott@devbox:/tmp/ghgo$ wc -l file_list* | sort -rn
322753 total
128657 file_list_example_vendor_test
92131 file_list_example_vendor
52079 file_list_example
49886 file_list
Here is the full code in all its glory:
#! /bin/bash
rm -r /tmp/ghgo
mkdir /tmp/ghgo
cd /tmp/ghgo
# The GitHub API only provides the first 1000 results
# https://developer.github.com/v3/search/
# There's also a sleep to be a good citizen and avoid rate limits
echo; echo "Retrieving list of repositories from GitHub..."
for page in $(seq 1 10); do echo "Retrieving page $page"; curl "https://api.github.com/search/repositories?q=language:go&sort=stars&per_page=100&page=$page" 2>/dev/null > $page; sleep 10; done
# Pull all needed data out of the huge json structures sent back
echo; echo "Parsing data..."
for page in $(seq 1 10); do cat $page | jq -c '.items | .[] | {name: .full_name, stars: .stargazers_count, cloneurl: .clone_url, created: .created_at, updated: .updated_at}' >> summary; done
# Extract info in easy format to use
for page in $(seq 1 10); do cat $page | jq -r '.items | .[] | {a: .clone_url, b: .full_name} | to_entries | map(.value) | join(",")' >> clone_info; done
# Parse into clone commands
cat clone_info | awk -F, '{print "git clone " $1 " repos/" $2}' > clone_cmds
# Clone all repositories
echo; echo "Cloning all repositories..."
cat clone_cmds | bash
echo; echo "Gathering basic stats..."
# Repos per organization or person
for org in $(ls repos/); do echo $(ls repos/$org | wc -l) $org >> org_counts; done
echo; echo "Top repo count per org or person:"
cat org_counts | sort -rn | head -n 10
# Times created
for line in $(cat summary); do echo $line | jq -r '[.created,.name] | join(" ")' >> created; done
echo; echo "Earliest 10 created repos:"
sort created | head
echo; echo "Latest 10 created repos:"
sort -r created | head
# Graph created date by month
cat created | cut -d'-' -f1-2 | sort | uniq -c | sed 's/^\s*//' > created_graph_input
# Times updated
for line in $(cat summary); do echo $line | jq -r '[.updated,.name] | join(" ")' >> updated; done
echo; echo "Oldest 10 updated:"
sort updated | head
echo; echo "Latest 10 updated:"
sort -r updated | head
# Graph updated date by day
cat updated | cut -d'T' -f1 | sort | uniq -c | sed 's/^\s*//' > updated_graph_input
echo; echo "Looking for usage of unsafe, reflect, and CGo..."
# Find all non-test, non-vendored, non-example go source files
find repos -iname "*.go" -type f | tee file_list_example_vendor_test | egrep -v '(.*_test.go$|/test/|/testdata/)' | tee file_list_example_vendor | egrep -v '/(Godeps|_?vendor|_?third_party|3rdparty|external)/' | tee file_list_example | egrep -v '/_?examples?/' | sed 's/ /\\ /g' > file_list
# Look for import statements with "unsafe" in them
# The strange sed invocation escapes filenames with spaces in the middle
for file in $(cat file_list); do egrep -H '^(import ( _)?)?\s*"unsafe"$' "$file" >> res_unsafe; done
cat res_unsafe | cut -d'/' -f2 | sort | uniq -c | sort -rn > unsafe_by_org
cat res_unsafe | cut -d'/' -f2-3 | sort | uniq -c | sort -rn > unsafe_by_repo
echo; echo "Top org usage of unsafe:"
head unsafe_by_org
echo; echo "Top repo usage of unsafe:"
head unsafe_by_repo
# Look for import statements with "reflect" in them
for file in $(cat file_list); do egrep -H '^(import ( _)?)?\s*"reflect"$' "$file" >> res_reflect; done
cat res_reflect | cut -d'/' -f2 | sort | uniq -c | sort -rn > reflect_by_org
cat res_reflect | cut -d'/' -f2-3 | sort | uniq -c | sort -rn > reflect_by_repo
echo; echo "Top org usage of reflect:"
head reflect_by_org
echo; echo "Top repo usage of reflect:"
head reflect_by_repo
# Look for //#cgo
for file in $(cat file_list); do egrep -H '//#cgo' "$file" >> res_cgo; done
# Files might have multiple lines that match, but we only count each file once
cat res_cgo | cut -d':' -f1 | sort | uniq | cut -d'/' -f2 | sort | uniq -c | sort -rn > cgo_by_org
cat res_cgo | cut -d':' -f1 | sort | uniq | cut -d'/' -f2-3 | sort | uniq -c | sort -rn > cgo_by_repo
echo; echo "Top org usage of CGo:"
head cgo_by_org
echo; echo "Top repo usage of CGo:"
head cgo_by_repo
I also created a LibreOffice spreadsheet file that I used to generate the graphs, which can be found here.
Conclusion and Further Research
There’s a whole lot more information that could be gleaned from the data given by GitHub and what exists in the repositories themselves. I haven’t done much with this yet, but might do another post with some further metrics. I did have some ideas:
- Speed of change relative to number of stars
- Number of forks relative to number of stars
- Repository size, including number of files and just disk size
- Usage of all packages in the standard lib
- A Graph of package usage across GitHub
There’s a sizable and growing community of gophers out there, and it’s getting bigger by the day. I was suprised to see the kind of diversity that exists, including major infrastructure projects like docker, kubernetes, and etcd, open source books, databases, internet proxies, graphics libraries, and more. I couldn’t be more excited for 2016.